
AI ENGINEERING & OCR
High-Volume Legacy Digitization (1M+ Documents)
1. THE CHALLENGE: The "One Million" Bottleneck
The client faced a backlog of 1,000,000+ legacy contracts stored in mixed formats (scanned images, PDFs, office docs).
The Constraint: Cloud APIs (OpenAI/Google) were ruled out due to strict GDPR/Data Sovereignty requirements and prohibitive costs at this scale.
The Trade-off: Traditional OCR (Tesseract) was fast but failed on handwriting and complex tables. Modern GenAI (Vision LLMs) was accurate but computationally too expensive to run on 1M documents.
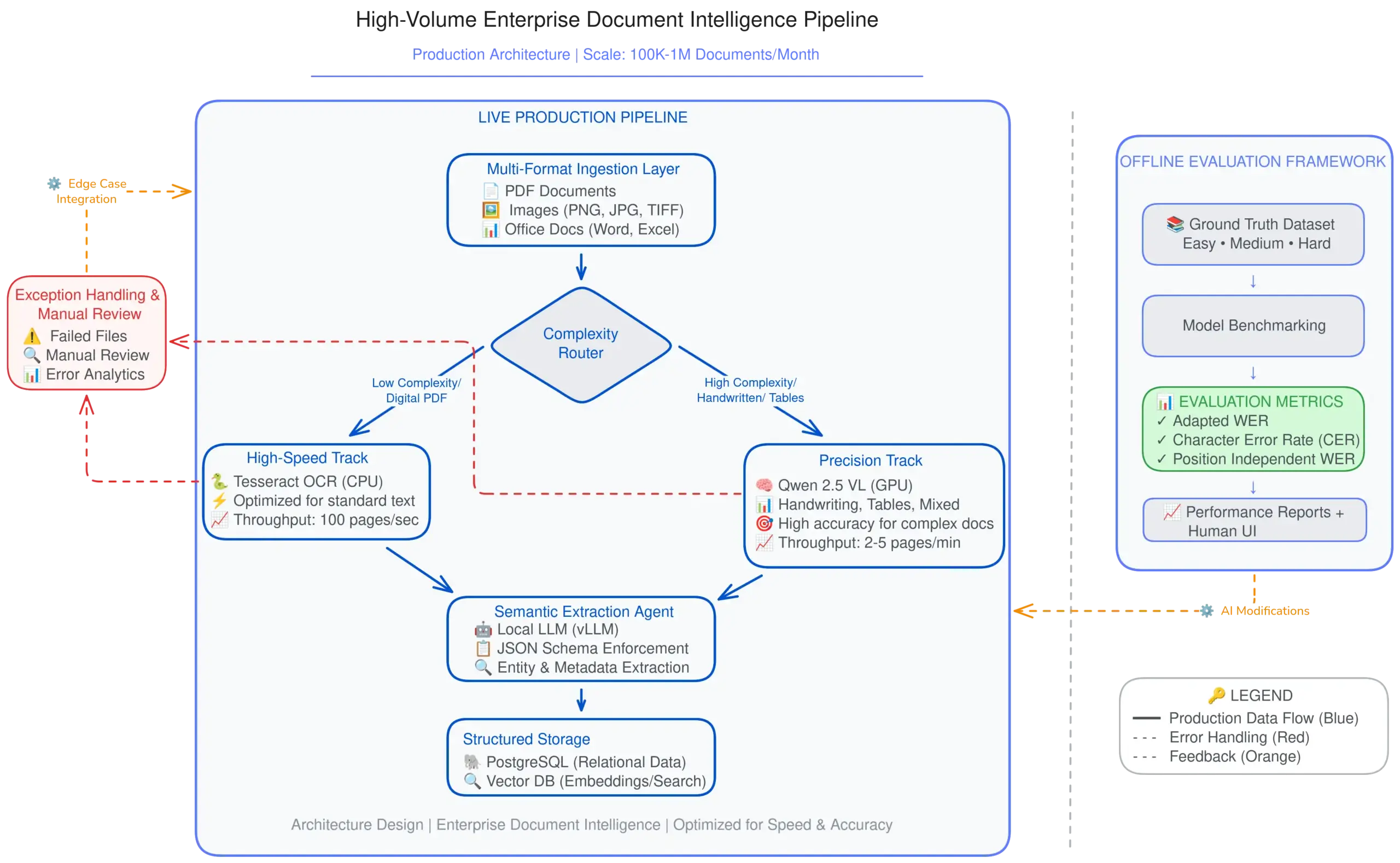
2. THE SOLUTION: The "Complexity Router" Architecture
We engineered a Hybrid Pipeline that optimizes for the “Goldilocks Zone” of cost and accuracy. Instead of treating every document the same, an intelligent Router analyzes complexity pre-inference.
Track A (High-Speed): Standard typed documents (~70% of volume) are routed to Tesseract (CPU-optimized). This ensures near-instant processing for simple files.
Track B (High-Fidelity): Documents containing handwriting, complex tables, or artifacts are routed to Qwen 2.5 VL (GPU-accelerated). This Vision LLM achieves near-human perception but is reserved only for files that need it.
Result: A 10x throughput increase compared to a pure-LLM approach, with zero compromise on accuracy.
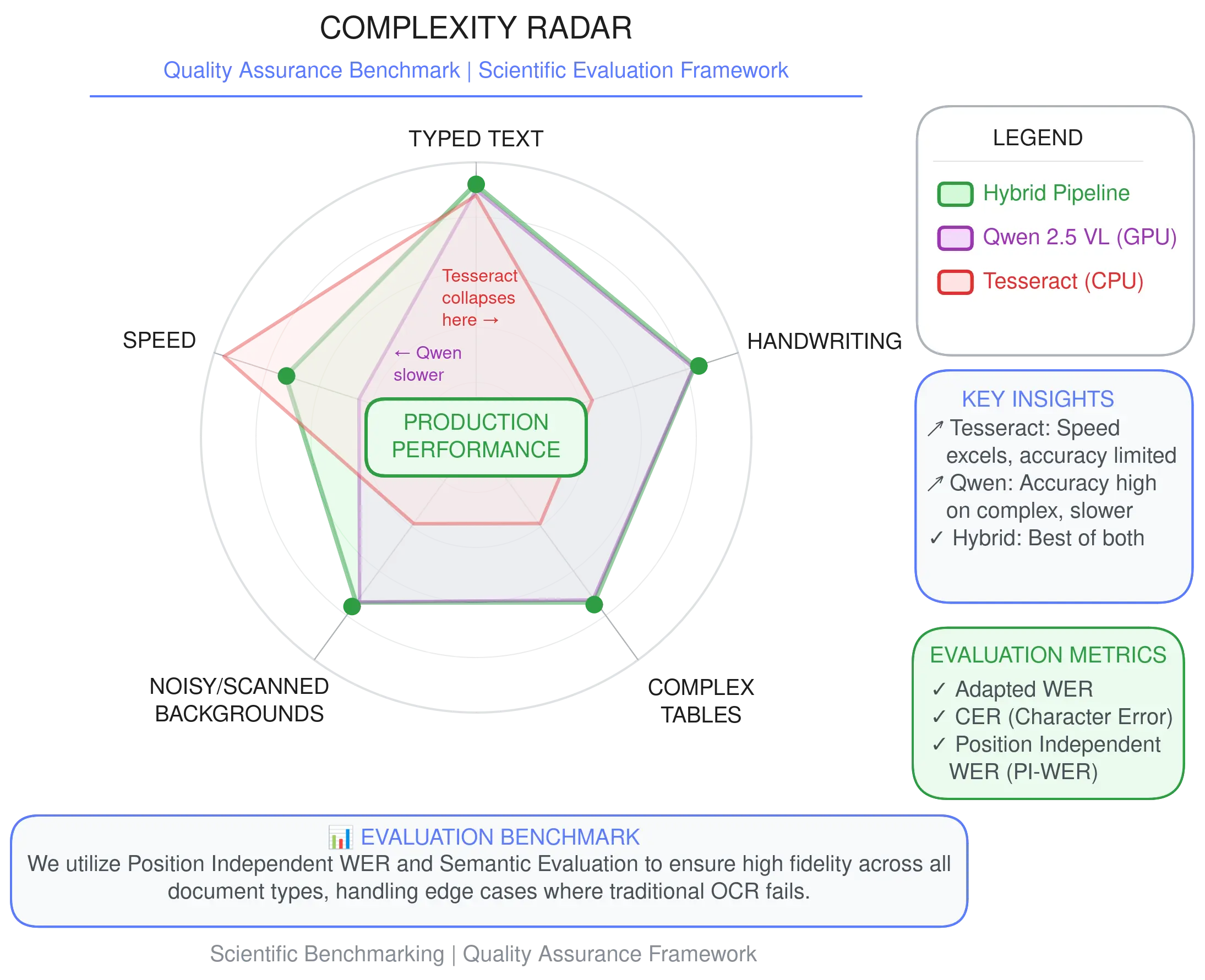
3. SCIENTIFIC EVALUATION & BENCHMARKING
We did not guess; we measured. The pipeline was validated against a “Golden Master” dataset divided into three tiers:
Easy: Clean, typed text.
Medium: Mixed fonts, slight skew.
Hard: Handwritten notes, dense tables, coffee stains.
The Metrics:
To ensure data integrity, I utilized a multi-dimensional scoring framework:
CER (Character Error Rate): For raw text fidelity.
WER (Word Error Rate)
Position Independent WER (PI-WER): Critical for table extraction where layout matters more than linear sequence.
LLM as a Judge Qualitative Metrics
A custom “Side-by-Side” UI allowed human reviewers to validate the AI’s confidence scores against the original PDF during the calibration phase.
4. INTELLIGENT CLASSIFICATION & RELIABILITY
Extracting text is useless if you don’t know what the document is. We initially trained a custom Sentence Transformer (SBERT) for document classification. While accurate, it proved too rigid for the client’s evolving document types.
The Pivot: We switched to a Local LLM with Few-Shot Prompting (In-Context Learning).
This allowed us to update classification rules dynamically by changing the prompt, rather than retraining a model. It offered superior flexibility while maintaining high reliability.
Resilience: The system is wrapped in a robust Error Handling framework. Failed extractions trigger an auto-retry loop with aggressive logging, ensuring no document is silently dropped.
5. THE OUTCOME
The system successfully processed the backlog of 1 Million+ documents entirely on-premise.
Speed: Achieved a 10x throughput increase compared to previous estimates.
Cost: Reduced GPU reliance by 60% via the Hybrid Routing strategy.
Compliance: Zero data leakage. 100% GDPR/Data Sovereignty compliant.
Tech Stack: Python | Docker | Airflow | PostgreSQL | vLLM
